 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Detecting and Preventing Hallucinations in Large Vision Language Models
Aug 18, 2023



Instruction tuned Large Vision Language Models (LVLMs) have significantly advanced in generalizing across a diverse set of multi-modal tasks, especially for Visual Question Answering (VQA). However, generating detailed responses that are visually grounded is still a challenging task for these models. We find that even the current state-of-the-art LVLMs (InstructBLIP) still contain a staggering 30 percent of the hallucinatory text in the form of non-existent objects, unfaithful descriptions, and inaccurate relationships. To address this, we introduce M-HalDetect, a (M)ultimodal (Hal)lucination (Detect)ion Dataset that can be used to train and benchmark models for hallucination detection and prevention. M-HalDetect consists of 16k fine-grained annotations on VQA examples, making it the first comprehensive multi-modal hallucination detection dataset for detailed image descriptions. Unlike previous work that only consider object hallucination, we additionally annotate both entity descriptions and relationships that are unfaithful. To demonstrate the potential of this dataset for hallucination prevention, we optimize InstructBLIP through our novel Fine-grained Direct Preference Optimization (FDPO). We also train fine-grained multi-modal reward models from InstructBLIP and evaluate their effectiveness with best-of-n rejection sampling. We perform human evaluation on both FDPO and rejection sampling, and find that they reduce hallucination rates in InstructBLIP by 41% and 55% respectively. We also find that our reward model generalizes to other multi-modal models, reducing hallucinations in LLaVA and mPLUG-OWL by 15% and 57% respectively, and has strong correlation with human evaluated accuracy scores.
Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
Apr 28, 2023


As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
NBDT: Neural-Backed Decision Trees
Apr 01, 2020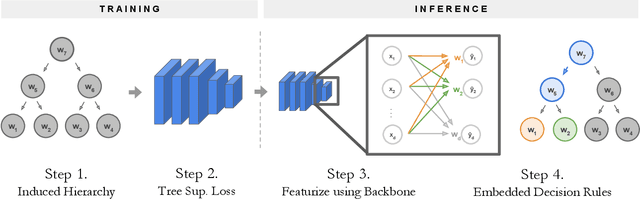
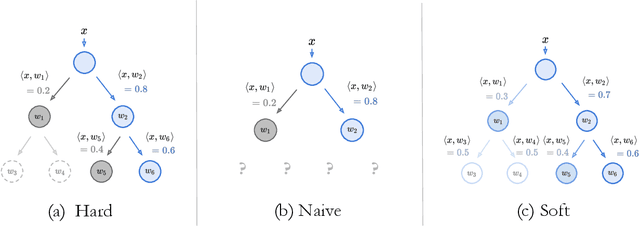
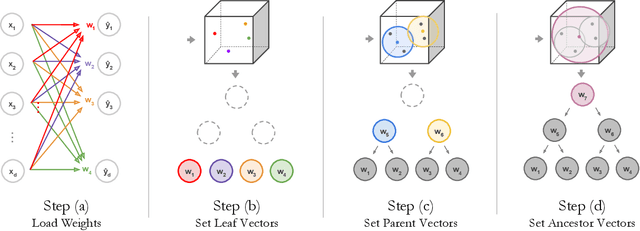

Deep learning is being adopted in settings where accurate and justifiable predictions are required, ranging from finance to medical imaging. While there has been recent work providing post-hoc explanations for model predictions, there has been relatively little work exploring more directly interpretable models that can match state-of-the-art accuracy. Historically, decision trees have been the gold standard in balancing interpretability and accuracy. However, recent attempts to combine decision trees with deep learning have resulted in models that (1) achieve accuracies far lower than that of modern neural networks (e.g. ResNet) even on small datasets (e.g. MNIST), and (2) require significantly different architectures, forcing practitioners pick between accuracy and interpretability. We forgo this dilemma by creating Neural-Backed Decision Trees (NBDTs) that (1) achieve neural network accuracy and (2) require no architectural changes to a neural network. NBDTs achieve accuracy within 1% of the base neural network on CIFAR10, CIFAR100, TinyImageNet, using recently state-of-the-art WideResNet; and within 2% of EfficientNet on ImageNet. This yields state-of-the-art explainable models on ImageNet, with NBDTs improving the baseline by ~14% to 75.30% top-1 accuracy. Furthermore, we show interpretability of our model's decisions both qualitatively and quantitatively via a semi-automatic process. Code and pretrained NBDTs can be found at https://github.com/alvinwan/neural-backed-decision-trees.